
MANUAL INQUIRY
Need ClaudeCode or GPT recharge help?
Use the inquiry pages for ClaudeCode, GPT recharge, assisted purchase, and team sourcing.
Automatic payment is not configured. Pricing, region support, and timing are confirmed manually.
[ComfyUI]Mochi: Commercially Available! The Largest Open-Source Video Generation Model to Date, 10 Billion Parameters & High-Fidelity Motion & Strong Prompt Following
Source: Public Account Author Polang
Recently, Genmo AI released their latest video generation model: Mochi 1 Preview. Mochi is an open advanced video generation model with high-fidelity motion and strong prompt following capabilities. Mochi 1 significantly narrows the gap between open video generation models and closed-source models. It's released under the Apache 2.0 open-source license, allowing free commercial use for individuals and businesses. The 480p base model is currently available on HuggingFace. Mochi 1 HD is planned for release by year-end. Additionally, Genmo AI announced completion of a $28.4 million Series A funding round led by NEA.
- • Online Experience: https://genmo.ai/play
- • Model Weights: https://huggingface.co/genmo/mochi-1-preview
- • github:https://github.com/genmoai/models
As a leading video generation model, Mochi 1 is highly competitive compared to leading closed-source models. The currently released 480p preview version has the following advantages:
- • Prompt Following: Extremely high alignment with text prompts, ensuring generated videos accurately reflect given instructions. This enables users to control characters, settings, and actions in detail.
- • Motion Quality: Mochi 1 generates videos up to 5.4 seconds long at 30 frames per second with smooth playback, high temporal coherence, and realistic motion patterns.
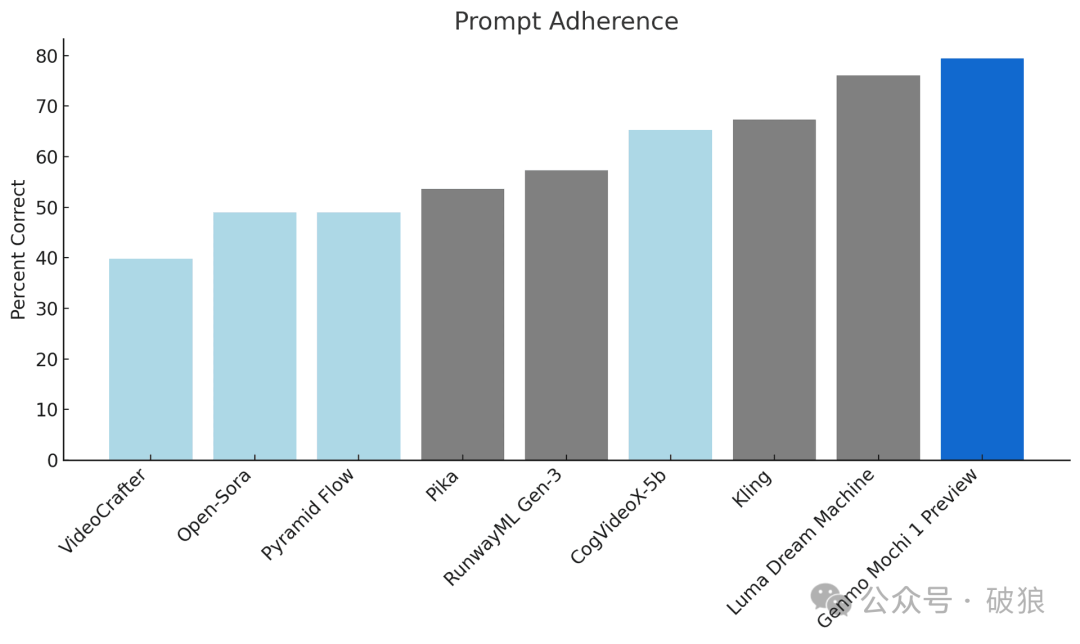
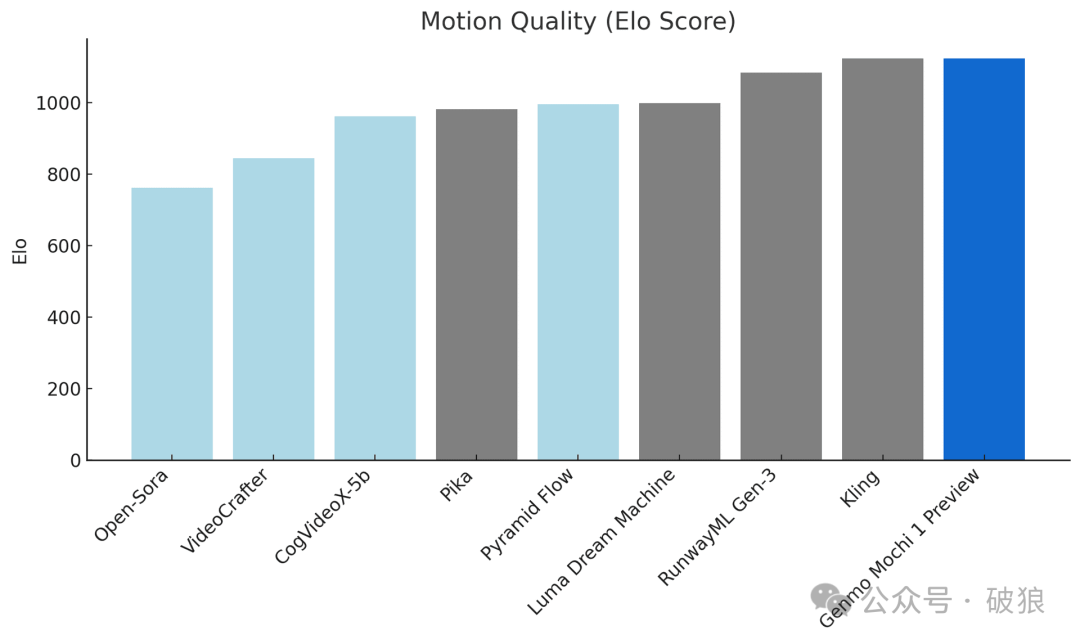
Mochi 1 employs a 10 billion parameter diffusion model based on a novel Asymmetric Diffusion Transformer (AsymmDiT) architecture. It's the largest publicly released video generation model to date, featuring simple architecture and easy modification.
Also open-sourced alongside Mochi 1 is a video VAE. This VAE can compress videos to 1/12 of their original size through 8x8 spatial compression and 6x temporal compression, converting them into a 12-channel latent space.
This process not only dramatically reduces data volume, but also retains sufficient information to enable generative models to operate effectively in latent space. This efficient compression approach is crucial for ensuring the model can run on resource-constrained systems, while also providing a powerful tool for the video generation field.
AsymmDiT efficiently processes user prompts and compressed video tokens by simplifying text processing and concentrating the neural network's capabilities on visual reasoning. AsymmDiT simultaneously attends to text and visual tokens through multimodal self-attention, and learns separate MLP layers for each modality, similar to Stable Diffusion 3. However, the visual stream uses a larger hidden dimension, with nearly 4 times the number of parameters as the text stream. To unify modalities in self-attention, Mochi uses non-square QKV and output projection layers. This asymmetric design reduces memory requirements during inference.
Unlike many current modern diffusion models that use multiple pretrained language models to represent user prompts, Mochi 1 uses only a single T5-XXL language model to encode prompts.
Mochi 1 jointly reasons over a context window containing 44,520 video tokens under full 3D attention. To position each token, the model extends learnable Rotary Position Embeddings (RoPE) to 3 dimensions. The network learns mixed frequencies for spatial and temporal axes end-to-end.
Meanwhile, Mochi 1 also draws on cutting-edge advances in language model scaling, including SwiGLU feedforward layers, query-key normalization for enhanced stability, and sandwich normalization to control internal activations.
The current 480p video model may experience slight deformation and distortion in edge cases involving extreme motion. Mochi 1 is optimized for realistic styles, so it performs poorly on animated content. Genmo AI states that this Mochi 1 preview release showcases the capabilities of the 480p base model. This is just the beginning—they plan to release the full version of Mochi 1 (including Mochi 1 HD) by year's end. Mochi 1 HD will support 720p video generation, improved fidelity, smoother motion, and address edge cases like deformation in complex scenes.
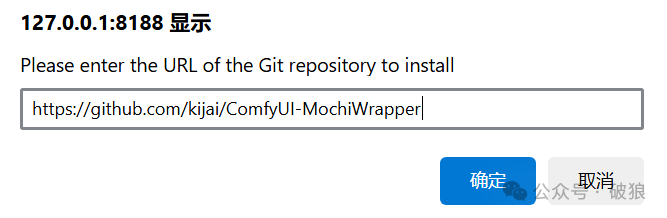
Community member @kijai has already pioneered support for Mochi experience in the ComfyUI plugin ComfyUI-MochiWrapper. First, install ComfyUI-MochiWrapper through the plugin manager. Models will auto-download on first run; if download fails, refer to the following model locations:
- • Plugin address: https://github.com/kijai/ComfyUI-MochiWrapper
- • t5xxl_fp8 model: Shared with SD3 and Flux, needs to be placed in ComfyUI/models/clip directory. Address: https://huggingface.co/mcmonkey/google_t5-v1_1-xxl_encoderonly/resolve/main/t5xxl_fp8_e4m3fn.safetensors?download=true
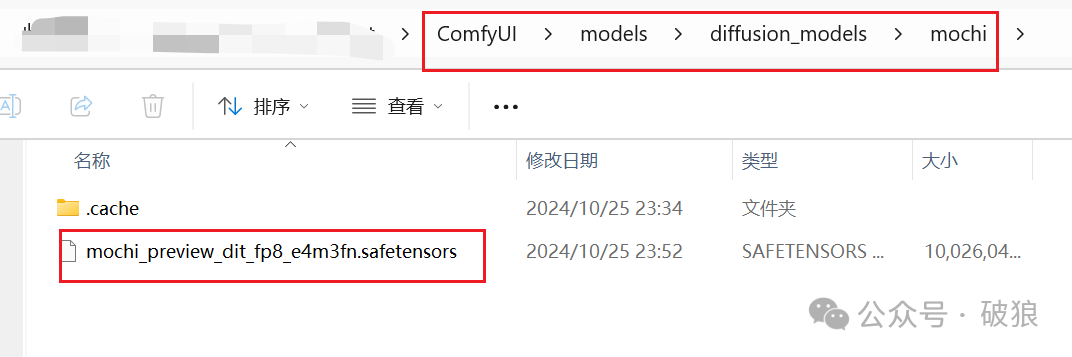
- • mochi model: Download and place in ComfyUI/models/diffusion_models/mochi directory. Address: https://huggingface.co/Kijai/Mochi_preview_comfy/tree/main
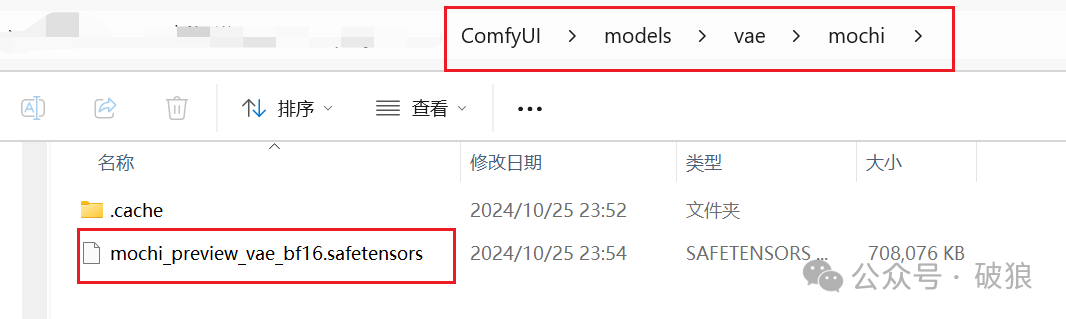
- • mochi vae model: Download the model and place it in the directory ComfyUI/models/vae/mochi. Link: https://huggingface.co/genmo/mochi-1-preview/resolve/main/vae.safetensors?download=true

The current plugin can fit within 20GB VRAM based on video frame count, incorporating an experimental tiled decoder borrowed from CogVideoX-diffusers code that allows for higher frame counts. The author claims to have achieved up to 97 frames, with a default tile size of 2x2 grid. For acceleration, you can also use flash_attn, pytorch attention (sdpa), or sage attention, with sage being the fastest.
The current workflow can be downloaded from LIBLIB platform: https://www.liblib.art/modelinfo/987eebc84cad4fa79503601bb3f7cadb?versionUuid=b7a7b0f93c7646fa9e18aeb5e9ff6ea2
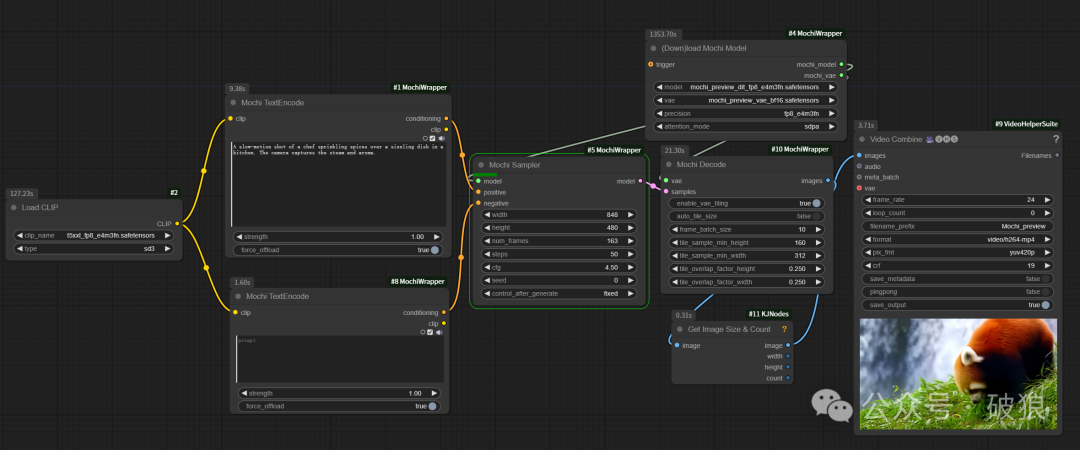

Note: The entire generation process is quite time-consuming - generating one video with 24G takes approximately 30 minutes.
Additionally, LIBLIB platform now supports online SD3.5 workflow experience. I've uploaded a workflow supporting Joy1 reverse inference + SD3.5 at: https://www.liblib.art/modelinfo/fb42d5cdd58644a2b28e86e2cfd28ac0?versionUuid=1189e755690f41dc933861cc9bc0c824
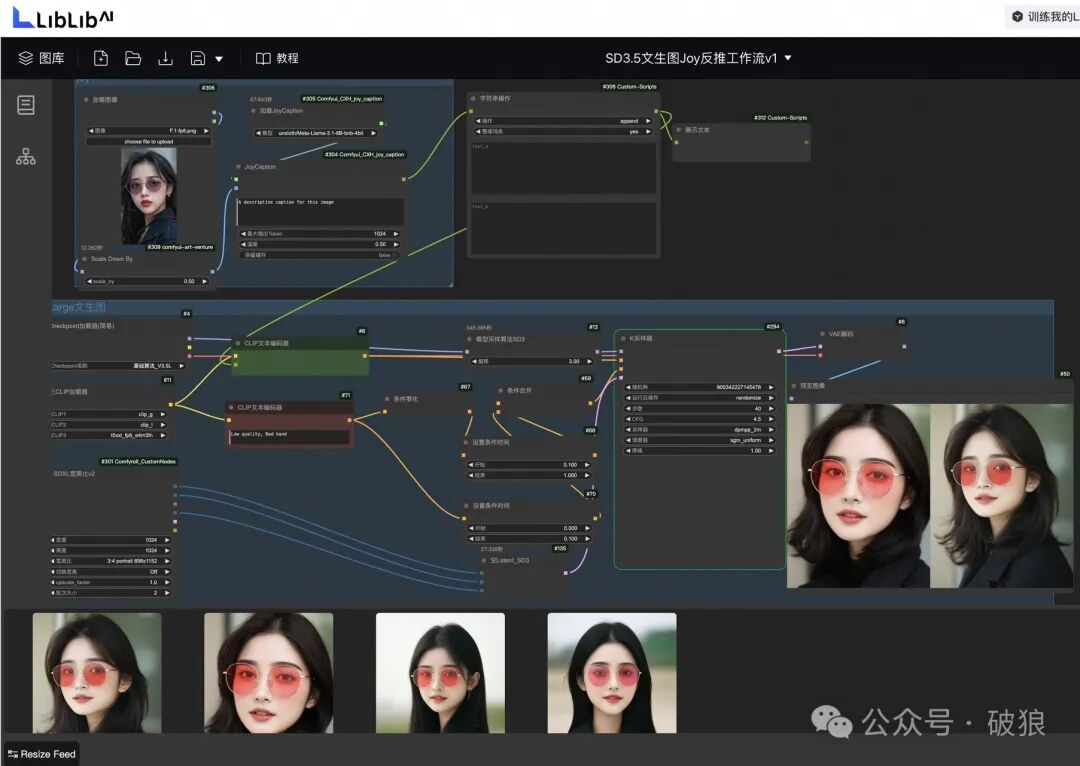
I won't comment on SD3.5 quality here - interested folks can experience it online directly. Follow Charliiai for more AI insights!
MANUAL INQUIRY
Need ClaudeCode or GPT recharge help?
Use the inquiry pages for ClaudeCode, GPT recharge, assisted purchase, and team sourcing.
Automatic payment is not configured. Pricing, region support, and timing are confirmed manually.