
Why this SAM 2 page is useful
This page is for builders searching for SAM 2, video segmentation workflows, and how foundation vision models combine with language models like GPT-4o in practical systems.
MANUAL INQUIRY
Need ClaudeCode or GPT recharge help?
Use the inquiry pages for ClaudeCode, GPT recharge, assisted purchase, and team sourcing.
Automatic payment is not configured. Pricing, region support, and timing are confirmed manually.
SAM 2 + GPT‑4o: Revolutionary Applications of Foundational Models in Computer Vision
Introduction
In recent years, the application of Foundation Models in the field of computer vision is driving a profound transformation. Whether it's autonomous driving, medical imaging, or content generation, visual prompting and multimodal interaction have become key to efficient and intelligent processing. Among these technological advances, the combination of Meta's Segment Anything Model 2 (SAM 2) and GPT-4o is undoubtedly a landmark development. Through visual prompting and cross-modal collaboration, these two models achieve automated segmentation and intelligent recognition of image and video data, greatly enhancing the model's work efficiency and application scope.
This article delves into the collaborative mechanisms between SAM 2 and GPT‑4o, offering a detailed overview of their practical applications and future potential in the field of computer vision. We will break down how the cascading architecture of the foundational models enables outstanding performance on tasks such as video segmentation and object tracking, and discuss the long‑term implications of these advances for the entire computer‑vision industry.
1. Introduction to the Core Models: What Are SAM 2 and GPT‑4o?
An Overview of SAM 2
Segment Anything Model 2 (SAM 2) is the latest computer‑vision model from Meta, designed specifically for object segmentation in images and videos. As an upgraded version of the original SAM, SAM 2 can segment any target object in any image or video without requiring additional training.
One of SAM 2’s standout features is its ability to perform real‑time segmentation, and it also delivers a marked boost in accuracy over its predecessor models.
TL;DR: SAM 2 can quickly and accurately segment target objects in any image or video, making it particularly suitable for video scenarios requiring real-time segmentation.
Figure: Real‑time Segmentation and Tracking of Pedestrians and Vehicles

Besides the improvements in segmentation performance, SAM 2 also comes with an open‑source SA‑V dataset that includes more than 51,000 videos and over 600,000 mask annotations. This dataset spans a wide range of application domains—such as medical imaging, satellite imagery, and marine‑life monitoring—providing the data foundation needed for the efficient deployment of SAM 2.

Illustration: The Core Features of SAM 2
GPT‑4o Overview
GPT‑4o is the latest, advanced large language model (LLM) specifically engineered for visual‑prompt tasks. Beyond generating natural language, GPT‑4o can handle complex visual prompts, enabling the model to forge deep connections across multimodal data such as text, images, and video.
When paired with SAM 2, GPT‑4o generates precise visual prompts that effectively guide SAM 2 in segmenting and recognizing objects within images and videos. For instance, a user can supply a simple instruction such as “label all the vehicles in the picture,” and GPT‑4o will parse that request and produce the corresponding prompt data. SAM 2 then uses these prompts to automatically carry out the segmentation and recognition tasks.
GPT‑4o’s multimodal capabilities make it a natural component of visual‑language models (VLMs), complementing SAM 2’s visual segmentation functions perfectly. The prompt data generated by GPT‑4o can help SAM 2 perform more intelligent segmentation and tracking in complex scenes, reducing the need for manual user intervention.
2. Key Innovations and Advantages of SAM 2
SAM 2’s innovation lies in its unified image‑and‑video processing architecture, which enables fully automatic object segmentation across static images and video streams and supports precise object tracking via visual prompts. Below, we’ll dive into several core breakthroughs of SAM 2 and the unique advantages they bring.
Unified Image‑and‑Video Model
One of SAM 2’s standout features is its unified model architecture, which treats images as single‑frame videos. This design enables seamless transition between image and video processing, allowing SAM 2 to tackle object segmentation tasks in both static images and dynamic video streams. As a result, the system boasts true cross‑media capabilities.
Additionally, this architecture leverages a “memory” component to retrospectively retrieve and track frame information that has already been processed in a video, ensuring consistency of objects across successive frames. As a result, SAM 2 can achieve highly accurate object tracking throughout video sequences—even in scenarios involving rapid object motion, occlusions, or significant lighting changes—while maintaining stable segmentation performance.
Promptable Visual Segmentation Task
SAM 2 supports promptable visual segmentation tasks, meaning users can define the segmentation of a specific object in a video through prompts such as clicking on an object, drawing a bounding box, or providing a mask. Based on the given prompt, SAM 2 generates a “spatiotemporal masklet” on the designated frame and automatically propagates the segmentation result to the remaining frames of the video. This mechanism enables long‑duration video segmentation with only a few prompt points, dramatically improving operational efficiency.
For example, users only need to click a few points on the first frame of a video, and SAM 2 will automatically track and segment the corresponding objects throughout the entire clip. Experiments show that, in many use‑case scenarios, just three prompt points are enough to achieve full‑duration object segmentation. This “minimal‑interaction” design not only lowers the user’s effort but also dramatically boosts segmentation efficiency.
Figure: Achieving full object segmentation using three prompt points.

Advanced Dataset (SA‑V Dataset)
To support model training, Meta has released the SA‑V dataset (Segment Anything‑Video Dataset), which comprises over 51,000 videos and more than 600,000 segmentation masks, covering a wide variety of scenes and object categories.
The extensive scale and rich diversity of the SA‑V dataset lay a robust foundation for SAM 2’s deployment across a wide range of fields—including medical imaging analysis, satellite remote sensing, autonomous driving, and content creation.
Exploring the Application Scenarios of the SA‑V Dataset.
- Medical Imaging: Leveraging AI for Cell and Organ Segmentation and Disease Detection.
- Satellite Imagery: Monitoring Natural Resources, Surface Changes, and Urban Development
- Autonomous Driving: Detecting Vehicles, Pedestrians, Roads, and Traffic Signals
- Content Creation: Providing Intelligent Segmentation Tools for Video Editing and Visual Effects Production
Through training on massive video datasets, SAM 2 demonstrates outstanding segmentation performance in these complex scenarios, supporting real‑time segmentation and object‑tracking needs across a variety of specialized application contexts.
Illustration: Example of video segmentation generated by SAM 2

Illustration: SAM 2 generated video segmentation example
3. The Role of GPT‑4o in Visual Prompts
GPT‑4o is a next‑generation large language model (LLM) whose role in visual prompting makes computer‑vision tasks more intelligent.
By collaborating with SAM 2, GPT‑4o can combine language processing with visual prompts, thereby establishing deep connections across multimodal data.
Below, we will focus on the core capabilities of GPT‑4o in visual segmentation tasks and its unique advantages.
Collaboration Between LLMs and LVMs
"GPT-4o is a multimodal large language model that can process textual data and interact with visual models such as SAM 2. When used in conjunction with SAM 2, GPT-4o can generate visual prompts (visual prompting) based on a user’s textual instructions and pass those prompts as input to SAM 2 to carry out subsequent segmentation and recognition tasks. For example, a user might enter “Mark all vehicles in the video,” and GPT-4o will parse the command, generate the relevant prompt, and enable SAM 2 to perform target segmentation within the video."
This collaborative relationship holds tremendous application potential in computer vision, particularly for tasks that demand integrated processing of both textual and visual information. GPT‑4o’s language‑understanding capabilities enable SAM 2 to parse and execute complex segmentation tasks with greater accuracy, thereby elevating the overall intelligence of the visual segmentation workflow.
"Cross-Modal Data Fusion"
GPT‑4o not only excels in language comprehension but also establishes strong connections across multimodal data (such as text, images, and video), making visual prompts smarter and more automated. For example, when processing long videos, GPT‑4o can identify specific scenes within the footage and automatically generate visual prompts for SAM 2 to perform segmentation and tracking tasks. This capability reduces the need for manual intervention, dramatically boosting data‑processing efficiency.
The Role of GPT‑4o in Real‑World Applications
- Object Detection and Recognition: GPT‑4o generates visual prompts to guide SAM 2 in automatically detecting and segmenting objects in images and videos.
- Video Summary and Analysis: GPT‑4o can assist SAM 2 in generating concise video summaries from visual cues, enabling users to quickly grasp the essential information in a video.
- Combining natural language and visual commands: By inputting natural language instructions, GPT‑4o can achieve precise segmentation and tracking of specific objects.
In complex scenarios that require dynamic adjustment of visual prompts, GPT‑4o’s multimodal collaboration capabilities can significantly reduce operational difficulty. For instance, in autonomous driving applications, GPT‑4o can generate visual prompts based on real‑time input commands, enabling SAM 2 to swiftly identify vehicles and pedestrians and continuously track targets within video streams.
Illustration: Object segmentation in video using SAM 2 combined with GPT‑4o
"This cross‑modal fusion capability broadens GPT‑4o’s prospects in the computer‑vision field and serves as a pivotal driver for boosting the efficiency and precision of visual segmentation."
4. Cascading Architecture of Foundational Models: Collaboration Between SAM 2 and GPT‑4o
In computer vision tasks, the cascaded architecture of foundational models is widely employed for processing multimodal data. Through a cascade structure, multiple models can collaborate, each leveraging its strengths to accomplish complex tasks. The collaboration between SAM 2 and GPT‑4o exemplifies this cascaded architecture; they respectively handle visual segmentation and prompt generation, thereby achieving intelligent processing of image and video segmentation.
The Concept of Cascading Base Models
"In a cascaded architecture, different models operate independently and accomplish tasks through clear input‑output relationships. GPT‑4o, as a visual prompt generation model, can create prompts tailored for visual tasks based on users’ natural‑language instructions and forward those prompts to SAM 2. Upon receiving the prompts, SAM 2 executes segmentation, tracking, and recognition according to the guidance. This cascaded setup enables GPT‑4o and SAM 2 to cooperate naturally on multimodal data."
The Advantages of Cascading Architecture
- Clear division of labor: GPT‑4o handles language understanding and prompt generation, SAM 2 focuses on visual segmentation, the task delineation between models is clear, enhancing collaborative efficiency.
- Reduce manual operations: Users can control SAM 2’s segmentation tasks through textual commands, thereby cutting down the manual labeling work involved in video processing.
- Adapting to Complex Scenarios: The cascade architecture can more effectively handle lighting variations, object occlusions, motion, and other challenging conditions in video data, thereby enhancing segmentation robustness.
"Real-World Applications of Visual Prompts"
"In practical applications, the cascaded architecture of GPT‑4o and SAM 2 has already demonstrated strong practical value. For example, in video content analysis, GPT‑4o can generate prompts for specific objects (e.g., “tag all blue vehicles”) and pass those prompts to SAM 2 to accomplish the identification and segmentation of every blue vehicle in the video. SAM 2 can then track these vehicles across each frame, achieving fully automated object annotation."
Use Cases
- Video Surveillance: In security monitoring systems, GPT‑4o can generate visual prompts from textual commands, allowing SAM 2 to automatically detect specific objects in surveillance footage (such as suspicious individuals, vehicles, etc.).
- Autonomous Driving: In autonomous driving systems, GPT‑4o can generate complex prompts (e.g., “detect obstacles in the lane”), helping SAM 2 achieve segmentation and recognition of lane‑bound targets, thereby ensuring driving safety.
- Content Editing: In the realm of video content creation, GPT‑4o’s prompt‑generation feature can streamline the object‑segmentation process in video editing, providing added convenience for post‑production.
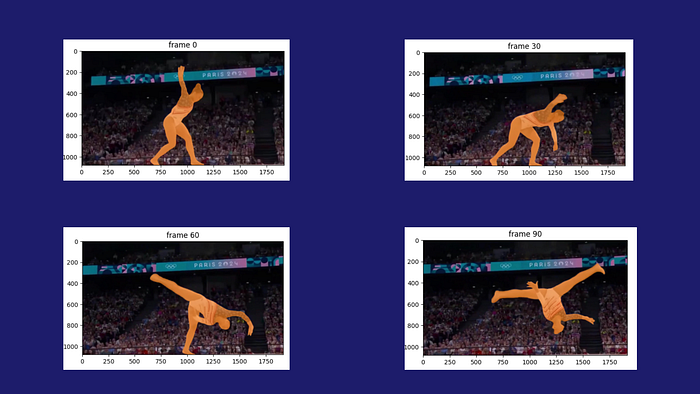
Illustration: Cross‑frame tracking and segmentation of objects in video
Through the collaborative work of GPT‑4o and SAM 2, the cascaded foundational model achieves cross‑frame object detection and tracking, and can swiftly adapt to evolving task requirements via real‑time prompts. This flexible, high‑efficiency architecture opens new possibilities for computer‑vision applications.
MANUAL INQUIRY
Need ClaudeCode or GPT recharge help?
Use the inquiry pages for ClaudeCode, GPT recharge, assisted purchase, and team sourcing.
Automatic payment is not configured. Pricing, region support, and timing are confirmed manually.